
Des chercheurs français de Facebook (Meta) ont trouvé un moyen de décoder la parole à partir des signaux cérébraux, en formant un modèle basé sur le deep learning et en utilisant des méthodes non invasives. Une avancée importante, à l’intersection des neurosciences et de l’intelligence artificielle.
Auteur / Autrice :
Des chercheurs de Meta parviennent à décoder les pensées avec un modèle spécial
Charlotte Caucheteux, Jérémy Rapin, Alexandre Défossez, Ori Kabeli, Jean-Rémi King sont des chercheurs dont les travaux récemment dévoilés devraient faire parler.
Et pour cause, « Décoder la parole à partir de l’activité cérébrale est un objectif attendu depuis longtemps dans les domaines de la santé et des neurosciences », selon l’équipe elle-même, qui vient de publier ses travaux dans Nature, le 5 octobre 2023.
Un objectif que ces chercheurs de Meta/Facebook travaillent à atteindre, non seulement pour la science, mais d’abord parce que « des milliers de personnes perdent chaque année leur capacité à parler ou même à communiquer » à cause d’accidents ou de maladies.
Parmi ces chercheurs, plusieurs français :
- Charlotte Caucheteux, passée par Louis Le Grand, la Sorbonne, HEC, puis Polytechnique et l’ENS
- Alexandre Défossez, déjà impliqué sur MusicGen (voir notre article), passé par l’ENS et l’INRIA
- Jérémy Rapin, passé par CentraleSupélec et l’ENS, avant un doctorat au CEA de Saclay
- Jean-Rémi King, passé par l’University College de Londres, puis l’ENS et l’Université Pierre et Marie Curie (UPMC)
Jusqu’ici, les interface cerveau-machine (ICM ou IHM) ont proposé de belles avancées, mais pas encore de vraies innovations de rupture capables de faire fortement progresser la capacité à communiquer de ceux qui en ont perdu la possibilité.
Ils citent notamment des travaux largement médiatisés, et des techniques d’avenir prometteuses récentes. Mais les chercheurs insistent sur la problématique que pose le côté invasif de ces méthodes : devoir passer par de lourdes (et dangereuses) opérations chirurgicales pour placer des capteurs dans la boîte crânienne, voire directement à l’intérieur du cerveau.
L’équipe de Meta s’est elle tournée vers les méthodes non-invasives, ne nécessitant pas de chirurgie, et en particulier via la magnétoencéphalographie (MEG) et l’électroencéphalographie (EEG). Car les deux « sont sensibles aux changements macroscopiques des signaux électriques et magnétiques provoqués dans le cortex ».
Deux techniques qui ont cependant des limitations en raison du bruit qu’elles génèrent, obligeant un travail conséquent qui limite leur efficacité : « concevoir des pipelines qui produisent des caractéristiques créées à la main, qui peuvent à leur tour être apprises par un décodeur formé sur un seul participant ».
Mais les chercheurs notent aussi un défaut commun aux méthodes invasives et non-invasives : elles se concentrent toujours sur un patient individuel, pour lequel elles forment un modèle dédié, qui n’est ensuite pas applicable à un ensemble général.
Une nouvelle méthode pour comprendre les signaux cérébraux sans chirurgie, puce, ni implant
Les chercheurs de Meta veulent eux proposer une autre approche qui reprend les dernières avancées majeures autour du deep learning, du machine learning et plus largement de l’intelligence artificielle.
Leur méthode propose ainsi « de décoder la parole à partir d’enregistrements cérébraux non invasifs ». Ceci en utilisant un modèle sur-mesure fait d’« une architecture unique » entraînée sur un grand nombre de personnes (et non-pas une seule).
Et « des représentations profondes de la parole apprises avec un apprentissage auto-supervisé » basée sur du « contrastive learning » (inspiré de CLIP de OpenAI), en utilisant une grande quantité de données vocales.
Autre particularité : les chercheurs se sont concentrés sur des personnes sans problème de communication (« sains ») pour former leur modèle. Ceci « afin de concevoir une “deep-learning architecture” » qui relève efficacement deux défis majeurs :
- Le fait que les enregistrements cérébraux non invasifs peuvent être extrêmement bruyants et variables d’un essai à l’autre et d’un participant à l’autre
- Le fait que la nature et le format des représentations du langage dans le cerveau restent largement inconnus
Ainsi : « Nous formons un seul modèle pour tous les participants, partageant la plupart des poids à l’exception d’une couche spécifique au participant. »
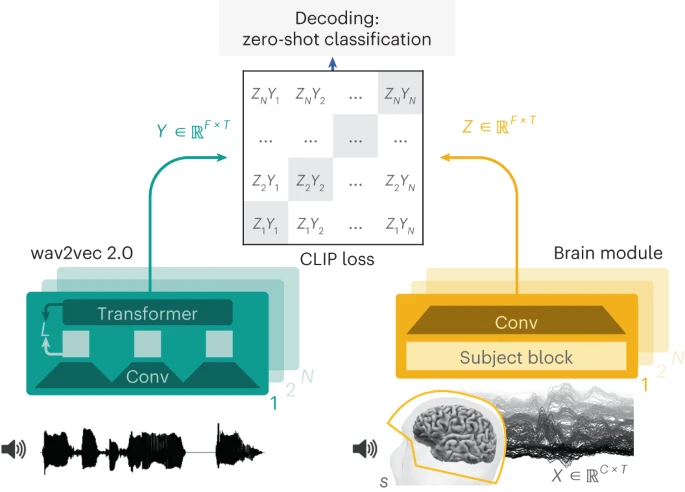
Dans le détail, leur méthode repose sur l’enregistrement via MEG ou EEG des signaux cérébraux émis par 175 volontaires pendant qu’ils écoutaient des histoires et/ou des phrases isolées. L’ensemble (Brain Module sur le schéma) fait plus de 162 heures d’enregistrements cérébraux, et est divisé en quatre bases :
- Broderick, créée en 2019 : EEG, 128 capteurs, 19 sujets, 19,2 heures
- Brennan and Hale (2019) : EEG, 60 capteurs, 33 sujets, 6,7 heures
- Scheffelen (2019) : MEG, 273 capteurs, 96 sujets, 80,9 heures
- G.williams (2022): MEG, 208 capteurs, 27 sujets, 56,2 heures
Côté audio, les chercheurs ont utilisé la base Wav2vec 2.0, pré-entraîné sur 56 000 heures de parole dans 53 langues différentes.
Avec ces enregistrements, les chercheurs ont formé un modèle qui peut ensuite tenter de lire “dans les pensées” (très grossièrement) en comprenant et en interprétant ce que veulent dire les signaux cérébraux perçus.

Les résultats obtenus par les chercheurs montrent que le modèle créé peut identifier, à partir de 3 secondes de signaux obtenus via MEG, le segment vocal correspondant avec une précision allant jusqu’à 41% sur plus de 1 000 possibilités distinctes en moyenne parmi les participants.
Un score qui monte à plus de 80% dans les meilleurs cas. Mieux, cela permet au modèle de décoder des mots et des expressions absents de l’ensemble qui a servi à sa formation !
Des résultats qui se rapprochent largement de la précision obtenue dans les études utilisant des méthodes invasives, comme des implants cérébraux. Les chercheurs sont d’ailleurs satisfaits de leurs résultats, et de l’avenir que ces recherches ouvrent :
« Dans l’ensemble, ce décodage efficace de la parole perçue à partir d’enregistrements non invasifs trace une voie prometteuse pour décoder le langage à partir de l’activité cérébrale, sans exposer les patients à un risque de chirurgie cérébrale. »
Pour aller plus loin :