
Des chercheurs de Stanford et de Adobe ont développé ActAnywhere, une nouvelle intelligence artificielle qui permet d’extraire un élément en mouvement et de substituer l’arrière plan en gardant une cohérence dans les images de la vidéo.
Auteur / Autrice :
Adobe avance dans l’intelligence artificielle
Ces dernières semaines, on a surtout entendu parler de Adobe pour le mariage raté avec Figma. Plus d’un an après le projet officialisé en septembre 2022, le géant avait dû renoncer à son deal à 20 milliards de dollars.
Adobe avait cependant dévoilé l’intelligence artificielle Firefly il y a quelques mois, donnant au grand public un outil gratuit de génération d’images très intéressant.
En fait, le groupe infuse essentiellement des améliorations IA dans ses principaux logiciels (Photoshop, Illustrator, Express…) au gré de mises à jour plus ou moins importantes.
Cette fois, un nouveau projet mené conjointement par Adobe et une équipe de l’université de Stanford dévoile « ActAnywhere ».
ActAnywhere, une nouvelle IA pour modifier les vidéos
Avant de créer ActAnywhere, Adobe et Stanford sont partis d’un constat :
« Générer un arrière-plan vidéo adapté au mouvement du sujet au premier plan est un problème important pour l’industrie cinématographique et la communauté des effets visuels. »
La principale difficulté vient que « cette tâche implique de synthétiser un arrière-plan qui s’aligne sur le mouvement et l’apparence du sujet au premier plan, tout en respectant l’intention créative de l’artiste ». Une tâche « qui nécessite traditionnellement des efforts manuels fastidieux ».
Pour régler en partie ce problème, les chercheurs ont développé ActAnywhere, un modèle qui automatise le processus : « Notre modèle exploite la puissance des modèles de diffusion vidéo à grande échelle et est spécifiquement adapté à cette tâche. »
Dans le fonctionnement, ActAnywhere utilise d’abord une séquence de segmentation du sujet au premier plan en entrée et une image qui décrit la scène souhaitée comme condition. De là, le modèle va produire une vidéo cohérente avec des interactions réalistes entre le premier plan et l’arrière-plan.
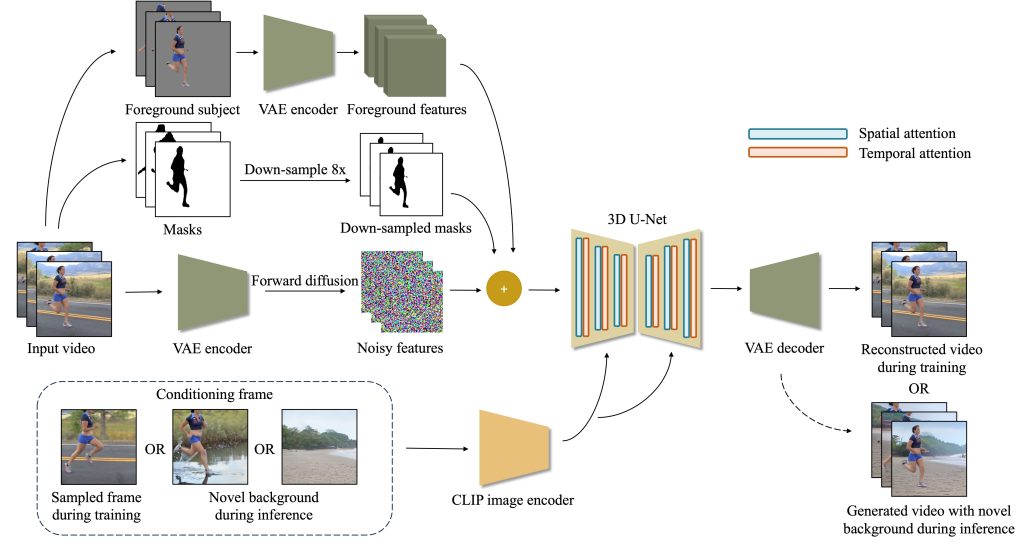
Un modèle entraîné sur un ensemble de données contenant plus de 2,4 millions de vidéos d’interaction « sujet-scène ». Fait intéressant, ActAnywhere fonctionne bien avec des sujets principaux humains qu’avec des objets non humains, comme des canards.
Voici plusieurs exemples de ActAnywhere :
- D’abord, un canard qui nage en surface transformé en un canard qui marche à côté d’un feu :

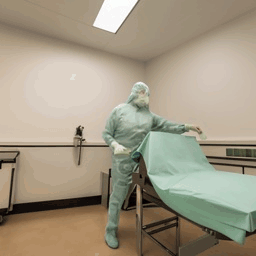
- Un chercheur qui déplace des choses transformés en quelqu’un qui place des draps sur un lit :
- Une femme sur un jet-ski qui est placée sur un cheval :

- Une joggeuse sur route placée sur une plage :

Des exemples comme ceux-ci, les auteurs en proposent des dizaines dans la publication dédiée. On voit donc que si la qualité est loin d’être parfaite, les premiers résultats promettent une transposition vidéo simplifiée dans un futur proche.
Pour en savoir plus sur ActAnywhere :