
Snapchat dévoile à son tour son intelligence artificielle de génération de vidéos, quelques semaines après Sora d’OpenAI, Lumiere de Google et beaucoup d’autres IA vidéo équivalentes. Le résultat de ce premier projet semble pour le moment loin d’être au niveau en terme de qualité.
Auteur / Autrice :
Snapchat dévoile à son tour son IA vidéo
C’est peut-être le nom que l’on ne pensait pas voir du tout sortir du bois dans le domaine de l’intelligence artificielle générative vidéo, en ce moment : Snapchat !
On avait eu OpenAI et son modèle SORA la semaine dernière, Lumiere chez Google (venu succéder à Phenaki) un peu plus tôt, fin janvier. On a eu Motion chez Leonardo fin décembre. Pika 1.0 de Pika Labs fin 2023 et la domination de la Gen-2 de Runway sur toute l’année dernière. On a aussi eu des projets venus de Meta (Emu-video) et Nvidia (VideoLDM).
Et c’est vrai que il y a quelques semaines, même TikTok y avait été de son modèle d’IA vidéo, avec MagicVideo-V2.
Dans ce pléthorique contexte, pourquoi alors être surpris que Snapchat avance aussi ses pions sur ce qui pourrait devenir un service standard d’ici quelques années… avec ses gagnants et ses perdants, et un marché où rien n’est acquis à personne pour le moment.
D’autant que Snapchat n’est pas un novice en terme d’IA d’image, et avait par exemple dévoilé une suite de produits destinés à enrichir l’expérience de ses utilisateurs, Dreams, avec des remix de portraits boostés à l’intelligence artificielle.
Tout ce qu’il faut savoir sur Snap Video
Avec l’axe de développement choisi par l’équipe derrière Snap Video, l’objectif est d’améliorer la fidélité du mouvement généré, ainsi que la qualité visuelle et l’évolutivité de la vidéo.
Alors les chercheurs sont partis du framework EDM pour s’intéresser aux pixels « spatialement et temporellement redondants », et prendre « naturellement » en charge la génération vidéo.
Ils pensent en revanche que U-Net, présenté début 2023 comme « l’architecture révolutionnaire pour la segmentation d’images », s’adapte mal lors de la génération de vidéos « ce qui nécessite une surcharge de calcul importante ». Et quiconque a entendu parler de Nvidia depuis 18 mois sait combien la puissance de calcul est un sujet.
Alors la team a repensé l’usage de Transformer et mis au point une nouvelle architecture « qui s’entraîne 3,31 fois plus rapidement que les U-Nets (et est environ 4,5 fois plus rapide en inférence) », inspirée des FITs. La diffusion est sensiblement reparamétrée et optimisée.
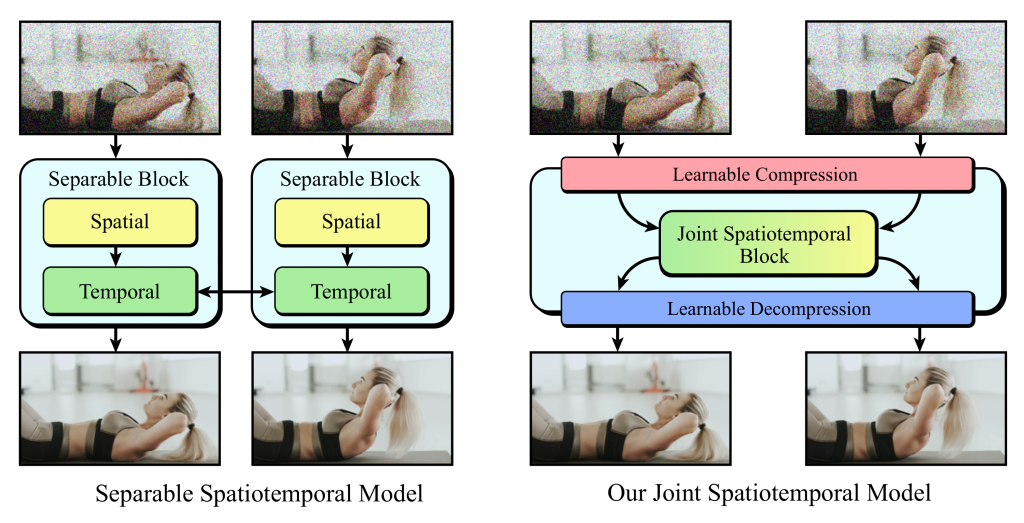
Une tentative technologique qui permettrait de former « efficacement » un modèle texte-vidéo avec des milliards de paramètres « pour la première fois », d’atteindre « des résultats de pointe » et de « générer des vidéos avec une qualité et une cohérence temporelle nettement supérieures », notamment en termes de complexité du mouvement.
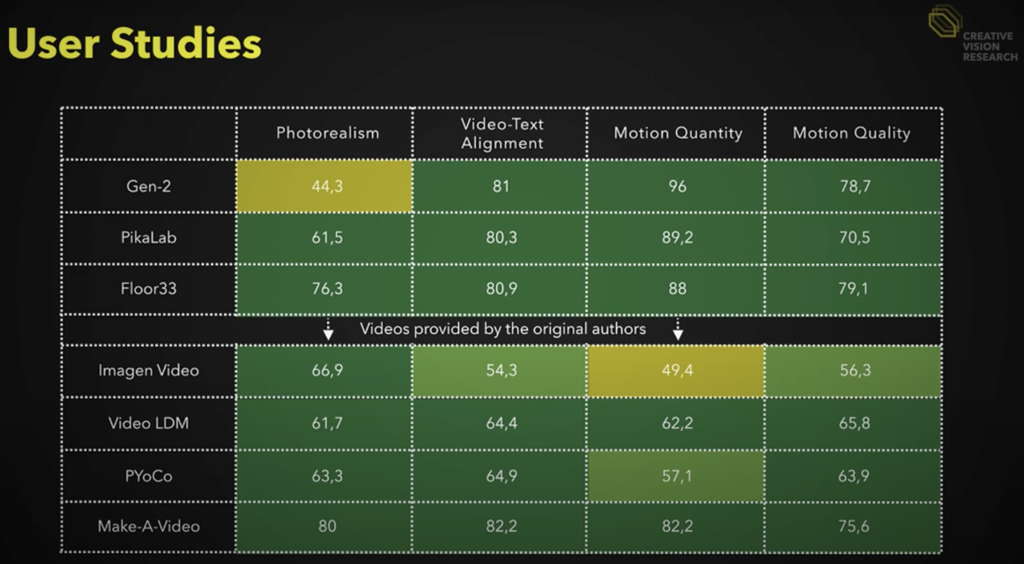
Des tests-utilisateurs auraient montré que Snap Video était « largement préféré » par rapport aux autres technologies les plus récentes. Des tests réalisés avant Sora (qui n’est cependant qu’une suite de jolies vidéos de teasing jusque là, rappelons-le).
Enfin, pour montrer les vidéos générées par l’IA Snap Video en action, les chercheurs ont eu la bonne idée d’en faire une vidéo diffusée sur Youtube (ce qui est très loin d’être cas de tous les projets du genre) :
Une vidéo qui va plus loin que les seuls exemples, et compare aussi Snap Video à des technos citées en début d’article, comme Pika, Runway Gen-2 Video LDM de Nvidia, ou à Stable Video Diffusion (le modèle vidéo de Stability AI dérivé de la techno Stable Diffusion).
Pour en savoir plus sur Snap Video :