
Bientôt finie la triche avec ChatGPT ? Avec SynthID, DeepMind réinvente le filigrane du texte généré par IA. Une technologie aussi appliquée au son, à l’image et à la vidéo.
Auteur / Autrice :
Rendre identifiable le texte généré par une IA
Depuis que ChatGPT est sorti, l’IA est devenu le cauchemar de nombreux métiers, des enseignants, qui voient les élèves utiliser une nouvelle méthode de triche ultra efficace, aux moteurs de recherche, qui voient des spammeurs utiliser l’IA pour générer des millions de pages pour tenter d’en tirer des revenus publicitaires.
Et depuis, beaucoup cherchent des solutions pour rendre détectable le texte généré par IA. Une pratique largement déployée sur les images générées via IA, avec notamment l’initiative de Meta lancée en février dernier (et basée sur sa technologie propriétaire Stable Signature). Mais une image est un fichier simple à filigraner, et plus difficile à modifier pour quelqu’un qui voudrait retirer ou rendre indétectable ce filigrane (aussi appelé watermark).
Pour le texte, les choses sont différentes. Comment filigraner une phrase ? C’est impossible. Un paragraphe, c’est un peu plus envisageable, mais la moindre modification apportée pourrait rendre la tentative caduque. À l’échelle d’un texte, c’est faisable, mais c’est encore largement sujet à la manipulation.
Un problème qu’avait abordé OpenAI dès début décembre 2022, à peine 10 jours après le lancement de ChatGPT (qui utilisait alors GPT-3.5). Une vaine tentative qui avait été abandonnée par la start-up dans les mois suivants, face notamment aux capacités bien plus avancées de GPT-4.
Tout savoir sur SynthID
Une nouvelle tentative sérieuse de rendre détectable le texte vient d’être dévoilée, deux ans maintenant après ChatGPT (une sorte de nouveau milestone qui pourrait en rappeler un autre, basé sur un certain « JC »).
Cette nouvelle technologie se nomme SynthID, et vient de chez Google DeepMind, l’entité IA de Google dirigée par Demis Hassabis (Demosthenes de son vrai nom), qui vient par ailleurs de recevoir le prix Nobel de chimie, au début du mois.
« SynthID filigrane et identifie le contenu généré par l’IA en incorporant des filigranes numériques directement dans les images, l’audio, le texte ou la vidéo générés par l’IA. »
SynthID est donc une technologie de watermarking globale des contenus générés par IA, qui traite le texte, mais aussi l’image et la vidéo, et – plus surprenant – l’audio. Un dernier point très intéressant à l’heure où plusieurs IA permettent de cloner la voix de n’importe qui avec quelques secondes d’échantillons. SynthID est maintenant intégré à Lyria, l’IA de création musicale de Google (« tous les audios générés par l’IA publiés par notre modèle Lyria ont un filigrane SynthID intégré directement dans sa forme d’onde »).
Pour l’image et la vidéo, comme évoqué en début d’article, plusieurs solutions fiables sont déjà mises en place par de grands acteurs depuis un an, mais SynthID est intégré à Imagen 3 et Veo, les IA image et vidéo de la maison.
Enfin, SynthID peut rendre identifiable, mais aussi détecter les contenus générés par des IA équipés de SynthID (les IA de Google pour le moment donc).
Rendre identifiable le texte
D’un point de vue technique, SynthID s’appuie sur plusieurs modèles et algorithmes variés construits sur du deep learning. Il s’agit d’ailleurs d’une technologie encore « en version bêta », et même plutôt d’une « boîte à outils » qui « continue d’évoluer ».
Mais quid du texte ? DeepMind explique d’emblée que SynthID n’est « pas une solution miracle » pour résoudre les problèmes de désinformation liés à l’IA.
Et concernant le texte en particulier, « trouver une solution robuste pour filigraner le texte généré par l’IA qui ne compromet pas la qualité, la précision et la production créative a été un grand défi pour les chercheurs en IA. » annonce la présentation.
Pour expliquer comment SynthID peut rendre le texte IA détectable, les chercheurs rappellent le fonctionnement des grands modèles de langage (LLM) :
Un LLM génère du texte un token à la fois. Ces tokens peuvent représenter un seul caractère, un mot ou une partie d’une phrase. Pour créer une séquence de texte cohérent, le modèle prédit le prochain token le plus probable à générer. Ces prédictions sont basées sur les mots précédents et les scores de probabilité attribués à chaque token potentiel.
Par exemple, avec la phrase ‘Mes animaux préférés sont __.’ Le LLM pourrait commencer à compléter la phrase avec les tokens « chat », « chien », « lapin » ou « hamster », et chaque token reçoit un score de probabilité.
SynthID intervient lorsqu’il y a une gamme de tokens parmi lesquels choisir, en ajustant le score de probabilité de chaque jeton prédit. Mais seulement « dans les cas où cela ne compromettra pas la qualité, la précision et la créativité de la sortie » générée.
De là, le processus est répété au fil du texte généré, « de sorte qu’une seule phrase peut contenir dix scores de probabilité ajustés ou plus, et une page peut en contenir des centaines ».
Finalement, c’est la combinaison « des scores pour les choix de mots » et des « scores de probabilité ajustés » du modèle qui crée le filigrane dans le texte.
Point positif, la technique pourrait être utilisée à partir de trois phrases, même si DeepMind ne donne pas de minimum de mots associé. Et logiquement, plus le texte est long, plus « la robustesse et la précision de SynthID augmentent ».
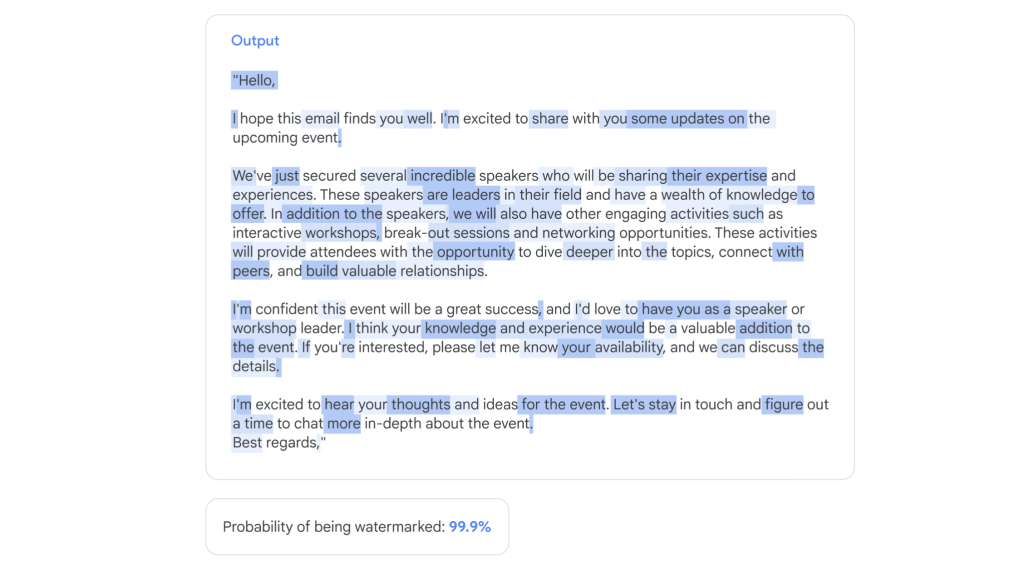
Le déploiement de SynthID dans Gemini dans un premier temps devrait permettre une première période d’essais grandeur nature.
Mais est-ce que DeepMind et Google vont s’associer avec d’autres grands acteurs pour ajouter SynthID à Claude, ChatGPT et autres ? Rien n’est moins sûr, car la technologie repose sur la connaissance profonde du modèle où elle est intégrée.
Pour en savoir plus sur SynthID :