
V-JEPA : Le dernier projet de Yann LeCun et Meta continue de progresser vers la création de modèle apprenant non pas sur d’immenses volumes de données mais sur une capacité d’observation et de compréhension proche de celle de l’humain.
Auteur / Autrice :
« Vous n’avez pas besoin de voir tout ce qui se passe dans le cadre, il peut vous dire conceptuellement ce qui s’y passe. »
Le jeudi 15 février 2024, trois grandes annonces ont été faites dans le domaine de l’intelligence artificielle :
- Gemini 1.5 de Google – Alphabet (voir)
- Sora de OpenAI (voir)
- V-JEPA de Meta
Mauvais timing pour ce troisième projet qui, bien qu’important, a perdu le combat de la visibilité face aux deux autres. Et pourtant, V-JEPA est un pas de plus dans le développement d’une IA multimodale et performante par Meta, dans la lignée des ambitions de Mark Zuckerberg, de son équipe FAIR et de la vision du français Yann LeCun, qui pilote le projet.
Un projet où l’on retrouve (presque comme toujours chez Meta AI) de nombreux français : Adrien Bardes (INRIA, ENS), Quentin Garrido (ENS), Nicolas Ballas (ENS, les Mines) et Jean Ponce (professeur à l’INRIA, l’ENS, passé par Stanford et le MIT).
V-JEPA, le dernier projet de Yann LeCun
Dans la continuité de JEPA début 2022, en juin 2023, Yann LeCun, Chief AI Scientist chez Meta dévoilait le projet I-JEPA (Image Joint Embedding Predictive Architecture). Un outil de computer vision qui présentait des résultats équivalents ou supérieurs avec une méthodologie différente :
« Par exemple, nous formons un modèle de transformateur visuel de 632 millions de paramètres en utilisant 16 GPU A100 en moins de 72 heures, et il atteint des performances de pointe pour la classification low-shot sur ImageNet, avec seulement 12 exemples étiquetés par classe. »
Pour rappel, Yann LeCun est Prix Turing 2018 avec Geoffrey Hinton et Yoshua Bengio. Les français ont beaucoup entendu parler du premier (Hinton) lorsque celui-ci a quitté Google au printemps 2023 pour pouvoir avertir librement « des dangers de l’IA ». Les médias le désignent alors comme « le père fondateur de l’IA », et oublient le français et son apport au domaine.
De son côté, Yann LeCun est très visible de la communauté IA via Twitter, où il est très actif et où son éclairage et ses participations aux débats apportent énormément de valeur.

C’est dans ces échanges que beaucoup ont pu découvrir ce qui est désormais plus qu’une opinion mais un axe de recherche à part entière : Il est peu efficace de vouloir former une intelligence artificielle (un modèle) via l’agglomération pure de milliards de milliards de données quand on voit qu’un humain peut apprendre en profondeur un domaine en quelques livres, parfois même quelques chapitres.
Yann LeCun utilise aussi souvent l’analogie de l’enfant en bas âge, et du volume de données qu’il peut recevoir :
C’est ce constat qui introduit V-JEPA dès les premiers mots :
« En tant qu’êtres humains, une grande partie de ce que nous apprenons sur le monde qui nous entoure – en particulier au cours des premières étapes de notre vie – est glanée grâce à l’observation. »
Et dans les exemples cités immédiatement, la physique observable (simplement) et la lecture :
« Prenez la troisième loi du mouvement de Newton : même un nourrisson (ou un chat) peut avoir l’intuition, après avoir fait tomber plusieurs objets d’une table et observé les résultats, que ce qui monte doit redescendre.
Vous n’avez pas besoin d’heures d’enseignement ou de lire des milliers de livres pour arriver à ce résultat.
Votre modèle du monde interne – une compréhension contextuelle basée sur un modèle mental du monde – prédit ces conséquences pour vous, et il est très efficace. »
Une réflexion et une base de travail pour un objectif :
« Notre objectif est de construire une intelligence artificielle avancée capable d’apprendre davantage comme le font les humains.
En formant des modèles internes du monde qui les entoure pour apprendre, s’adapter et élaborer des plans efficacement au service de l’accomplissement de tâches complexes. »
Un modèle d’apprentissage et de compréhension, pas une IA générative
V-JEPA est un modèle « non génératif » (par opposition aux IA qui écrivent du texte, du code ou produisent des images et vidéos). Il est construit sur une approche d’apprentissage auto-supervisée, et entièrement pré-entraîné avec des données non étiquetées.
Un modèle qui apprend en prédisant les parties manquantes ou masquées d’une vidéo dans un espace de représentation abstrait. Un fonctionnement similaire à la façon dont l’architecture prédictive de I-JEPA comparait les représentations abstraites des images (plutôt que de comparer les pixels eux-mêmes).
Contrairement aux approches génératives qui tentent de combler chaque pixel manquant (une tâche lourde, peu efficace et consommatrice en ressources), V-JEPA va supprimer les informations imprévisibles, conduisant à une amélioration de l’entraînement et de l’efficacité des échantillons.
Dans le détail, V-JEPA n’a pas été formé pour comprendre un type d’action spécifique et y exceller. Non, V-JEPA a eu une formation (auto-supervisée) sur une série de vidéos et « a appris un certain nombre de choses sur le fonctionnement du monde », comme le fait un humain.
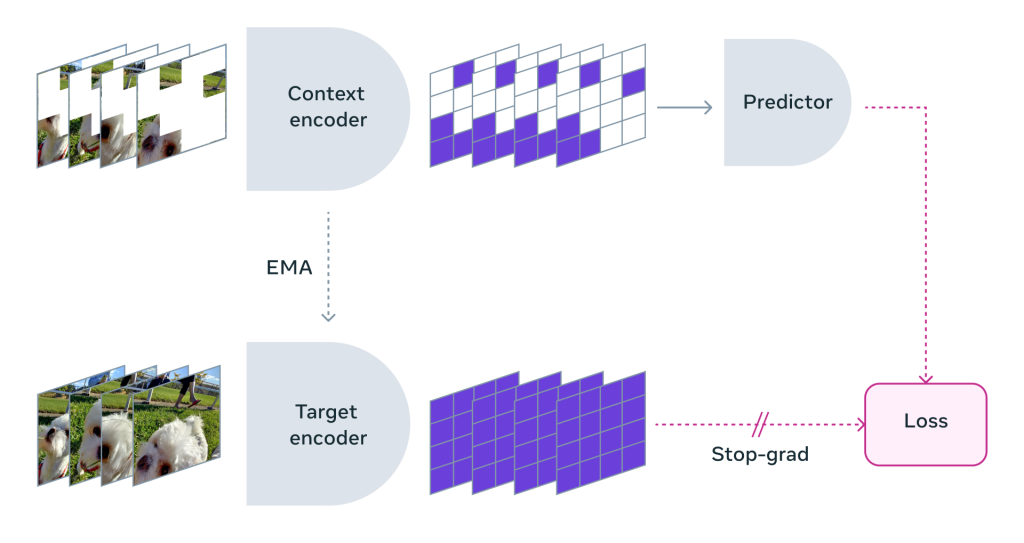
Et l’équipe de Meta a également soigneusement étudié la stratégie de masquage : « Si vous ne bloquez pas de grandes zones de la vidéo et que vous échantillonnez au hasard des correctifs ici et là, cela rend la tâche trop facile et votre modèle n’apprend rien de particulièrement compliqué sur le monde. »
L’équipe dit aussi qu’il est également « important de noter que dans la plupart des vidéos, les choses évoluent assez lentement au fil du temps ». Un point qu’on remarquait particulièrement dans les anciens dessins animés (avant le numérique), où l’animation est souvent concentrée sur un élément évoluant sur un plan essentiellement fixe. Plus largement, lorsqu’on filme un humain, le décor autour évolue assez peu à l’image.
De là, « si vous masquez une partie de la vidéo mais seulement pour un instant précis et que le modèle peut voir ce qui s’est passé immédiatement avant et/ou immédiatement après, cela rend également les choses trop faciles et le modèle n’apprendra presque certainement rien d’intéressant ». Alors l’équipe a utilisé une approche consistant à masquer des parties de la vidéo « à la fois dans l’espace et dans le temps », ce qui oblige V-JEPA à apprendre et à développer une compréhension de la scène dans son ensemble.
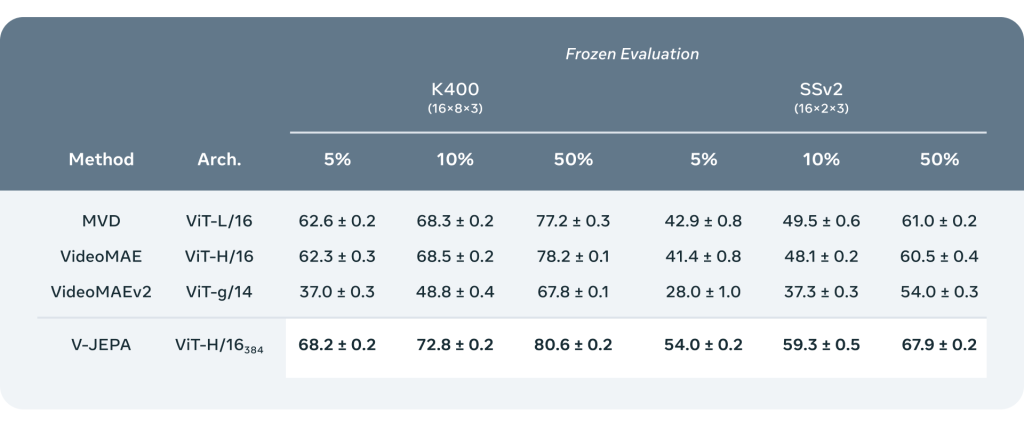
Meta propose ensuite une série de données d’évaluations qui intéresseront surtout les spécialistes.
Et conclut en rappelant que V-JEPA n’est qu’une étape, et que l’avenir sera multimodale :
Bien que le « V » de V-JEPA signifie « vidéo », il ne représente jusqu’à présent que le contenu visuel des vidéos. Une approche plus multimodale est une prochaine étape évidente, c’est pourquoi nous réfléchissons soigneusement à l’intégration de l’audio aux visuels.
Ce qui ne peut que rappeler ImageBind, cet autre projet de Meta dévoilé il y a un an.
Enfin, ces mots de conclusions :
Nous savons qu’il est possible de former des modèles JEPA sur des données vidéo sans nécessiter une supervision stricte et qu’ils peuvent regarder des vidéos comme le ferait un nourrisson : il suffit d’observer le monde passivement et d’apprendre beaucoup de choses intéressantes sur la façon de comprendre le contexte de ces vidéos, de telle sorte qu’avec une petite quantité de données étiquetées, vous puissiez rapidement acquérir une nouvelle tâche et la capacité de reconnaître différentes actions.
Le V-JEPA est un modèle de recherche et nous explorons un certain nombre d’applications futures. Par exemple, nous pensons que le contexte fourni par V-JEPA pourrait être utile pour notre travail sur l’IA incorporée ainsi que pour notre travail visant à créer un assistant d’IA contextuel pour les futures lunettes AR. Nous croyons fermement en la valeur d’une science ouverte et responsable, et c’est pourquoi nous publions le modèle V-JEPA sous la licence CC BY-NC afin que d’autres chercheurs puissent étendre ce travail.
Pour aller plus loin :