
Traitant le texte, l’audio, l’image, la profondeur, le mouvement et même la température, « ImageBind » de Meta est une première IA globale.
Auteur / Autrice :
Une intelligence artificielle pour les gouverner toutes, et dans les ténèbres, les lier
Lorsque Meta publie le document PDF présentant « ImageBind« , une chose frappe, l’accroche : « One Embedding Space To Bind Them All ». Soit en français « Un espace d’intégration pour tous les lier ».
Sauf que la formulation « To bind them all » est généralement associée à l’anneau unique – et maléfique – créé par Tolkien dans « Bilbo le Hobbit », et développé dans la saga du « Seigneur des Anneaux » : « Un Anneau pour les gouverner tous. Un Anneau pour les trouver. Un Anneau pour les amener tous et dans les ténèbres les lier. » A lire avec la voix VF de Gollum, pour le charme.
Cette parenthèse refermée, attaquons maintenant le sujet principal : Meta est hyperactif dans le domaine de l’intelligence artificielle depuis plusieurs semaines, et a dévoilé un nouveau projet ce 9 mai 2023 : ImageBind.
ImageBind est présenté par Meta comme « le premier modèle d’IA capable de lier des informations à partir de six modalités ». Une intelligence artificielle capable de prendre :
- Le texte
- L’image/vidéo
- L’audio
- La profondeur
- La chaleur d’un rayonnement infrarouge
- Les Inertial Measurement Units (IMU), qui calculent le mouvement et la position. Meta indique vouloir y coupler rapidement des capteurs 3D

Une intelligence artificielle globale, qui traite donc un environnement complet, sur le modèle de ce que font les humains en permanence : « ImageBind est une étape importante vers la construction de machines capables d’analyser différents types de données de manière holistique, comme le font les humains ».
Meta dévoile « ImageBind »
Comme nous, cette technologie va donc regarder, entendre et écouter, jauger dans l’environnement, et arbitrer ces différentes paramètres : « Il contribue à faire progresser l’IA en permettant aux machines de mieux analyser ensemble de nombreuses formes d’informations différentes ». Et Meta explique que ses IA multimodales devraient traiter tous les types de données possibles autour d’elles.
Mieux, même en étant ouvert à plusieurs dimensions d’interactions, ImageBind serait meilleur que les IA spécialistes de leur domaines : « ImageBind peut surpasser les modèles spécialisés antérieurs formés individuellement pour une modalité particulière ».
Et fort de ces capacités, Meta explique aussi que des générations faites sur certains types de données d’entrée (le texte par exemple) pourrait être utilisées pour renforcer d’autres types de données manquantes (la voix, ou la vidéo par exemple) : « les capacités multimodales d’ImageBind pourraient permettre aux chercheurs d’utiliser d’autres modalités comme requêtes d’entrée et de récupérer sorties dans d’autres formats ». Dans un fonctionnement d’apprentissage auto-supervisé.
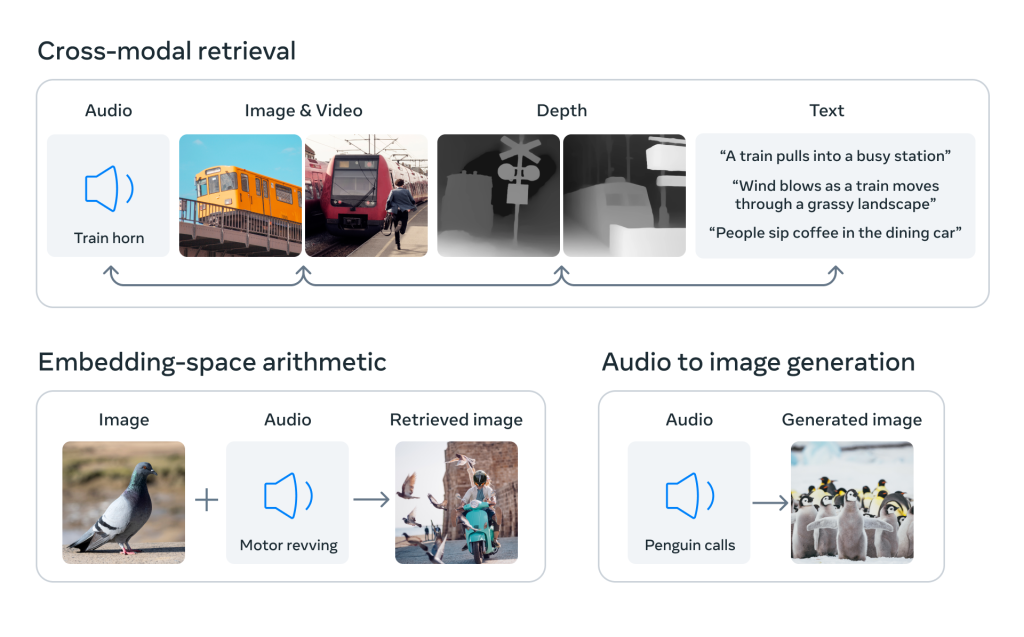
Et de cette compréhension multifactorielle, la possibilité de faire créer par l’IA de nouvelles choses : « créer des images à partir d’audio, ou créer une image basée sur les sons d’une forêt tropicale ou d’un marché animé ».
Et même plus : Meta imagine un monde où l’IA boosté avec la technologie ImageBind pourrait fournir « un moyen riche d’explorer les souvenirs, en recherchant des images, des vidéos, des fichiers audio ou des messages texte en utilisant une combinaison de texte, audio et image ». Les souvenirs ne seraient plus alors de vagues images brumeuses dans le cerveau, mais de riches animations multi-factorielles… à vivre dans un casque de réalité virtuelle ?
Une IA avec six sens, et open source !
Encore une fois, oubliez l’entreprise qui disperse ses colossaux profits dans l’édification d’un mon virtuel fantôme. Meta est aujourd’hui l’une des entreprises les plus pointues dans l’IA, et mieux encore, elle propose nombre de ses progrès en open source !
Dans ce sens, ImageBind rejoint une série récente d’outils d’IA open source de Meta, comme l’outil de computer vision DINOv2 (voir notre article), ou le projet Segment Anything Model (voir). Même LLaMA, le LLM “échappé” de Meta, est massivement utilisé par le communauté open source, comme s’en effrayait d’ailleurs un leak massif venu de chez Alphabet/Google la semaine dernière (voir).
Or, « ImageBind complète ces modèles car il se concentre sur l’apprentissage de la représentation multimodale. Il essaie d’apprendre un seul espace de fonctionnalités aligné pour plusieurs modalités, y compris, mais sans s’y limiter, les images et les vidéos. À l’avenir, ImageBind pourra tirer parti des puissantes fonctionnalités visuelles de DINOv2 pour améliorer encore ses capacités ».
Enfin, Meta attribue aussi à ImageBind des « capacités émergentes : « Notre modèle a de nouvelles capacités émergentes, ou comportement de mise à l’échelle, c’est-à-dire des capacités qui n’existaient pas dans les modèles plus petits mais qui apparaissent dans des versions plus grandes. Cela peut inclure la reconnaissance de l’audio qui correspond à une certaine image ou la prédiction de la profondeur d’une scène à partir d’une photo ».
Les « capacités émergentes », une idée générale attaquée il y a quelques jours seulement par une publication intitulée « Are Emergent Abilities of Large Language Models a Mirage? » : https://arxiv.org/abs/2304.15004
Enfin, Meta met à disposition une interface de test accessible via ce lien, qui propose des associations pré-enregistrées comme « image > audio » ou « audio > image ».
Pour aller plus loin :
- La publication : https://arxiv.org/abs/2305.05665
- Le document PDF (15pages) : https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
- La page officielle : https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
- Le GitHub : https://github.com/facebookresearch/ImageBind